バスロケーションシステムの維持費を1/10に! さくらのIoTを活用しバス位置情報をGoogleマップに提供
- 公的機関・その他

宇野自動車株式会社
- IoTサービス


今回はディープラーニング領域でさくらの高火力コンピューティングを利用しているIdein(イデイン)代表の中村晃一氏に、アスキー編集部 大塚とさくらインターネットの江草陽太氏、長谷川猛氏が、Ideinが持つ技術の特長や独自性、将来の可能性、さらに高火力コンピューティングに対する評価や新しい32GBモデルへの期待などをうかがった。(インタビュアー:アスキー編集部 大塚、以下敬称略)
※こちらの記事は2018年9月5日に ASCII.jpで公開された記事を再編集したものとなります。
文● 大塚昭彦/TECH.ASCII.jp 写真● 曽根田元
――まずはIdeinの事業領域や技術的な強みについて、簡単にご紹介いただけますか。
中村:Ideinは、ディープラーニング技術を安価なデバイスで使えるようにすることで、世界中に普及させることに取り組んでいるベンチャー企業です。画像認識や音声認識の処理を、従来の100分の1、1000分の1という価格帯のデバイスで、従来と変わらない精度、遜色のないスピードで実現するための技術を開発しています。
また、今年2月には大手自動車部品メーカーであるアイシン精機さんとの資本業務提携契約も締結し、自動車組み込み分野における研究開発も共同で行っています。
実際にわれわれがどんな世界を目指しているのかは、デモを見ていただいたほうがわかりやすいと思いましたので、今日はいくつかのデモを用意しています。
手にしているのはRaspberry Pi Zeroに画像認識モデルを組み込んだデバイス
まず1つめのデモは、600円くらいで買える「Raspberry Pi Zero」を使います。裏面にカメラモジュールを取り付けており、このカメラが捉えたモノが何なのかをリアルタイムに分類し、テキストで表示するというものです。画像認識処理ですね。
たとえば、このカメラでPCを写すと……「computer keyboard」と表示されました。会議室の窓に向けてみると「windows screen」や「windows shade」と認識していますね。Web検索したパンダの画面を写すと「giant panda」と出ます。現在のバージョンでは、これを平均96ミリ秒で処理できています。

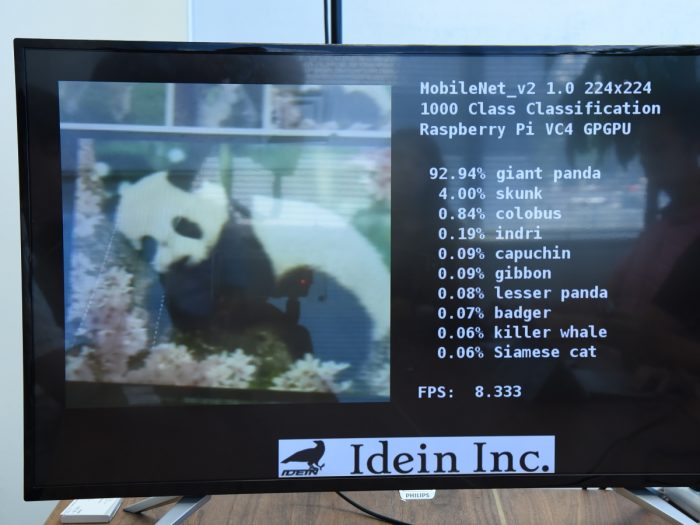
Raspberry Pi Zeroのカメラが写したものを瞬時に画像認識する。この写真はPC画面上のパンダを写したときの結果
――およそ0.1秒、一瞬ですね。これは画像をクラウドに送って処理してるんですか?
いいえ、すべてRaspberry Piのオンボードで動いていて、外部とは一切通信していません。この深層学習モデル自体はグーグルがWebで公開しているもの(MobileNet)ですが、それをIdeinの技術で最適化することで、リソースの少ないデバイスでもこのスピードで動かせるんです。
江草:完全にスタンドアロンで動いているんですね。すごい。
中村:Ideinの技術のポイントは「スピード」なんです。
グーグルが作ったこの画像認識モデル自体は、もともとはスマートフォンなどのハイスペックなデバイスで動かすことを想定したものです。そのままRaspberry Piに載せても重くてまともには動きません。しかし、それをわれわれの技術で最適化すれば、十分実用的なスピードで動かせるようになるわけです。
次のデモは、今お見せしたデバイスに「sakura.io」の通信モジュールを組み合わせたものです。こちらも同じくカメラ画像を分類するモデルが載っており、認識結果の情報だけをLTE網で送信しています。
長谷川:こちらも速いですね。カメラを向けると、PC側で瞬時に「water bottle」とか「coffee mug」とか表示されます。
sakura.ioの通信モジュールを組み込み、画像認識結果だけをLTE網で送信するデバイス

中村:sakura.ioの帯域幅ではカメラ画像そのものは伝送できませんが、認識した結果だけ、具体的にはそのモノが何かを表すID番号だけであれば十分に流せます。画像認識の処理がエッジデバイス(Raspberry Pi Zero)上で完結しているからこそ、このようなデモも可能になるわけです。
こんなふうにエッジデバイス側で高度な解析ができれば、フィールドにたくさんデバイスをばらまいてデータを収集したいときに役立ちますよね。sakura.ioのような安い回線を使ってデータ収集ができますから。
最後にもうひとつ、こちらは4000円ほどで買える「Raspberry Pi 3」です。このデバイス上で、カメラに写った人間の骨格や顔の向きを認識するモデル(姿勢推定モデル)を動かしています。
江草:これも十分なスピードで動きますねえ。面白いです。
中村:こちらも、従来の技術だとだいたい数十万円するコンピューターを使わなければ実現できませんでした。そうしたディープラーニング技術を数千円、数百円のデバイスで実用化し、利用の普及を促すというのがIdeinの取り組んでいることです。

――Ideinの技術によってリソースの少ない組み込みデバイスでも高度な(複雑な)深層学習モデルを動かせるというお話ですが、従来の技術とはどこに違いがあるんでしょうか。
中村:まず、アプローチが根本的に違います。組み込みデバイスに深層学習モデルを載せる場合、これまでのアプローチは「リソースの少ないデバイスに載るように、いかにモデルを小さくするか」というものでした。実際、多くの企業がこのアプローチで研究開発を進めていますが、それだとモデルそのものを簡素化することになるので、たとえば画像認識や音声認識の精度は下がってしまいます。
一方でIdeinのアプローチは、「リソースの少ないデバイスでもそのまま動かせるように、既存の深層学習モデルを最適化する」というものです。最適化によって既存のモデルとまったく同等の計算を行うモデルを作るので、精度は低下しません。
言い換えれば、これまでの組み込みAIは「必要な計算量をいかに削るか」を考えてきたわけですが、Ideinでは最適化コンパイラを用いて「同じ時間内で実行できる計算量をいかに増やすか」を研究しているわけです。
――「Ideinが持つ技術のポイントはスピード」だというお話もありました。組み込みデバイスでも実用上十分なスピードを実現するというわけですが、実際どのくらい速くなるんでしょうか。
中村:たとえばRaspberry Pi Zeroで、「TensorFlow」を用いてMobileNetを実行する場合、Ideinの技術を適用することで、通常のおよそ50倍、正確には49倍速く動かせます。まったく同じモデルを使って同じ計算をするんですが、49倍速く処理できるのです。
なので、Raspberry Piのような安価な組み込みデバイスを、タイミングがクリティカルな(瞬時に解析しなければならないような)用途に使えるようになります。そのほかにも、同じ時間内に複数の異なる解析を走らせる、あるいはもっと複雑な解析をするなど、幅広いアイデアが考えられますね。
江草:「49倍のスピード向上」というのは、最適化コンパイラによる効果がほとんどなんですか。
中村:最適化コンパイラによる効果と、Raspberry PiのGPUを効率的に使っている効果の両方ですね。「数学的なレベルでの高速化」と「ハードウェアに特化した高速化」の2つがあります。
数学的な高速化というのは、たとえばキャッシュパフォーマンスをいかに最適化するか、モデルを融合していかに演算量を減らすかといった工夫のことです。それと同時に、そのハードウェアにしかない特殊な回路などを駆使して高速化する工夫もする。その両方を掛け合わせて、Raspberry Pi Zeroならば49倍のスピードを実現しているわけです。
ハードウェアに特化した高速化で言うと、先ほどのデモでお見せした深層学習モデルは全体がGPUに載っています。それで何をしているかと言うと、ioctl(アイオーコントロール、Linuxでデバイスドライバを制御するシステムコール)を1回呼んだら、CNN(たたみ込みニューラルネットワーク)の上から下までを全部通るようにしています。
江草:ああ、なるほど!
――……えー、わたしはよくわかってないので(笑)、もう少し詳しく説明していただけますか。
中村:ニューラルネットワークモデルは多数のレイヤーで構成されていますよね。入力があったら1レイヤー目でこの計算をして、2レイヤー目でこの計算をして……と、いろんな計算を順番にやっていく仕組みです。
一般的な手法だと、このレイヤーごとにCPUがGPUにデータを送って、計算結果をCPUに戻して、またGPUに送って、戻して……と繰り返し処理していきます。そのたびにカーネルではioctlの呼び出しが発生するんですが、われわれはこのioctlの部分も全部GPUに載せてしまって、最初のioctlを呼び出すだけでCNNの全レイヤーを一気に計算してしまう仕組みにしているわけです。

――あっ、だから処理が速くなるわけですね。
江草:本来、GPUはソフトウェアの実行環境なのだけど、ハードウェアのパイプライン処理もGPU内でやってしまっているイメージですよね。
中村:そうですそうです。全部GPUに載っているので、CPUはGPUの処理が終わるのを待っているだけ、その間のCPU使用率はほぼゼロ%です。なので、CPUはディープラーニング以外の処理、たとえばポストプロセスの処理や通信周りのコントロールに使える空き状態になっています。
ちなみにRaspberry Pi ZeroのCPUはすごく遅くて、Raspberry Pi 3の40分の1くらいです。しかし、実は両者のGPUは一緒なので、GPUに全部送ってしまえば同じスピードで処理できるんです。
江草:それはすごい。
中村:これはわかる人にはわかる話ですね(笑)。
なお、Ideinがターゲットとしている組み込みデバイスはRaspberry Piだけではありません。先ほど触れた最適化コンパイラは汎用的な、どんなデバイスにも対応するものとして開発しており、CPU処理はこちらで最適化できます。それとは別に、Raspberry PiのGPU用に特化したニューラルネットワークのライブラリも開発したわけです。
ちなみにこのライブラリは、アセンブラから全部われわれが作りました。まずアセンブラを作って、ドライバを作って、ライブラリ群はアセンブラで……と。GPUのライブラリまで「手書き」する会社って、あまりないでしょうね。
長谷川:そういえば以前、Raspberry Piのアセンブラを作る記事をネットで読んだことがあるのですが……。
中村:それ、わたしの記事です(笑)。Raspberry Piのチップを作っているブロードコムがGPUのスペックを全部公開したことがあって、その技術資料に基づいてアセンブラを自作し、GPUで行列乗算をしてみる記事を書きました。そのアセンブラをベースに、うちのエンジニアがディープラーニング用に開発を続けて、現在に至っているわけです。
長谷川:そしてそのときの記事をわたしが読んでいた、と。
江草:最適化コンパイラを作っているのは、ハードウェア設計にも詳しい方なんですか?
中村:たとえばスパコンのコンパイラを開発していた人、半導体の露光装置を開発していた人など、メンバーはいろいろです。CTOは半導体に関わっていた人、わたし自身は東大でスパコンの研究をしていました。
江草:Ideinさんのアーキテクチャは、ソフトウェアだけでなくアルゴリズムも当然知っていないといけないし、「仮にハードウェア実装したらこうなるだろう」と想像できる人が設計していることを強く感じさせます。
中村:そうですね。同じ計算をするにしても、たとえばアルゴリズムにもデータの分割方法にも無数の選択肢があります。そして、そこには必ずトレードオフもあって、演算回数は減るけれど通信量が増える、メモリ使用量は増えるけど演算効率は上がるといった違いが生まれます。そうした無数の選択肢の中からどうすれば最も効率が良いのかを、マイクロベンチマークをひたすら取りながら、コンパイラとして実装していくのです。
こうしたものを自ら開発して動かすことの難しさは、わかる人にはわかります。なので、Ideinが持つ技術力の証明にもなっているんです。先ほどRaspberry PiのGPUライブラリの話をしましたが、これを開発したことでRaspberry Pi以外の組み込みデバイスの案件も舞い込んでくるようになりました。
Ideinオフィスの書棚には、ソフトウェアだけでなくAI/アルゴリズムやプロセッサ関連の専門書も並ぶ
――Ideinの技術によって、これまで組み込み分野では実現が難しかったアイデアも実現しそうです。実際に、どんなビジネスインパクトが与えられると思っていますか。
中村:ひとつはやはり「コストを下げられる」ことです。エッジデバイスの導入コスト、あるいは大量のデータをクラウドに転送する回線コストやクラウド利用料を引き下げ、組み込みAIのコストを最適化できると思います。
それから、実は多くの企業がPOC(実証実験)段階で自社開発したディープラーニングモデルを持っているんです。ただ、実用化に向けてそれをデバイスに載せようとしても、デバイスのリソースが少なくて載らない。そこで、先ほどお話しした「モデルを小さくする」アプローチで取り組むわけですが、その開発には何カ月もかかり、当然コストもかかる。しかもモデルを小さくした結果、精度が不十分なものになってしまうかもしれない。つまり、ここにディープラーニングの普及を阻害するボトルネックが生じているのです。
なので、もうひとつのインパクトとしては、世界中の企業に眠っている“POCで止まってしまったモデル”を、そのままデプロイして実用化できることだと考えています。Ideinの技術を使えば、がんばってモデルを小さくしなくても、いろいろと面白いアイデアが実現できますから。
――うまく実用化できなかった深層学習モデルがよみがえるかもしれない、それはインパクトが大きいですね。今後どのようにビジネス展開される計画なのですか。
中村:年内に「Actcast(アクトキャスト)」という新サービスをローンチしようと考えています。これは顔検出や人物検出、姿勢検出など、あらかじめわれわれが用意した学習済みモデルを提供するほか、ユーザーが保有するモデルも最適化してエッジで高速に動作させることができるクラウドサービスです。そのモデルをRaspberry Piやそのほかの組み込みデバイスにダウンロードするだけで、ノンコーディングですぐに使える環境を提供します。もちろんWebサービスと連携できるAPIも用意します。
幅広い用途が考えられますが、たとえばセキュリティ用途で「立入禁止の場所で人を検知したら通報する」、店舗マーケティングで「来店者の性別や年齢を特定してデータベースに記録していく」、工場の製造ラインならば「カメラ画像で不良品を仕分ける」とか。
中村:現状では、こうしたソリューションの多くが「画像をクラウドに吸い上げて、クラウドで分析する」アプローチです。そうなると通信料やクラウドの利用料が月額数万円、数十万円とものすごく高くなります。あるいは別のアプローチで、エッジ側に数十万円するデバイスを用意するか。いずれにしても手軽じゃないですよね。
Actcastならばエッジ側は数百円、数千円のデバイスで済むし、必要最低限の分析結果データしか通信しないので通信料も安く済む。したがって、前述したようなAIソリューションを非常に安く提供できます。Raspberry Piのようなポピュラーなデバイスと安価なサービスの組み合わせで、ワーッと広めたいと思います。
現在はこのActcastで配布する深層学習モデルの開発フェーズに入っており、そこで大量のGPUリソースが必要になるので、さくらの「高火力コンピューティング」を使わせてもらっています。われわれが配布したいのは高精度なモデル、つまり大規模なモデルですから、GPUクラスタとしてもそれなりの規模が必要だったのです。
――ここで高火力コンピューティングが使われているんですね。そもそもいつ頃から利用されているんですか。
中村:契約したのは昨年の10月です。実は2つ契約していまして、Ideinが単独で利用しているGPUクラスタと、資本業務提携先のアイシン精機さんと共同運用しているクラスタがあります。
アイシン精機さんとの取り組みの詳細はお話しできないのですが、自動車業界で今ホットな「自動運転」などの研究を進めるためには、大規模な分散クラスタが必要になります。1つの深層学習モデルを作るのに何日も待たされるようでは、激しい競争に勝ち残れませんから。そこでTesla V100のInfiniBandクラスタを構築し、アイシン精機さんとIdeinが共同で利用しています。
――高火力コンピューティングを採用される前はどうされていたのですか。
中村:それ以前はここ(オフィス内)にGPUマシンを並べていました。ただ、必要なクラスタの規模が大きくなってくると、どうしてもそれでは難しいところがありまして。社外サービスの利用を検討していたところに、さくらの須藤さん(高火力コンピューティングの事業責任者である須藤武文氏)と知り合いだったこともあって、契約に至りました。
長谷川:自社内にGPUクラスタを設置しようとすると、電源や排熱、騒音の問題がつきまとって辛い思いをされるとよく聞きます。Ideinさんもやはり同じでしたか?
中村:もちろんそうした問題もありましたし、そもそもさくらと同規模のクラスタを並べようと思ったらかなりの設備投資が必要です。そこにInfiniBandも欲しいとなると、投資額がさらに膨れ上がりますからね。
――さくら以外のサービスも検討されましたか。
中村:スポットで(時間単位で)借りるかたちのパブリッククラウドもひととおり検討しました。ただ、Ideinでは24時間、定常的にGPUクラスタを動かす使い方を想定していたのと、環境構築の自由度が低い点に課題がありました。それからやはりInfiniBandが使えるかどうか。InfiniBandを必須の要件にした時点で、ほとんどのクラウドサービスは選択肢から外れました。
長谷川:フレームワークは何を使用されていますか。
中村:分散学習のフレームワークにはPreferred Networksさんの「ChainerMN」を、共有ストレージにはNFSを使っています。NFSもInfiniBand上で動いているので、ノードからノードへデータをコピーするのがめちゃくちゃに速い。これは地味にうれしいですね。
長谷川:Ideinさんにご提供しているのは、56GbpsのFDR InfiniBandです。GPUクラスタは、24時間ずっと利用する想定だと他社よりかなりコストパフォーマンスが良いはずです。
――実際に高火力GPUサーバーを使ってみて、評価はいかがですか。
中村:評価ですか? えー……「速いなあ」(全員笑)。やはり速いのは気持ちいいです。

それまでは社内に置いた小さなマシンで、流れてくるログをのんびり眺めていたわけですよ。「だんだんモデルの精度が上がってきたなあ」とか言いながら。それが、さくらのクラスタを使えば一気にドワーッと流れるわけです。作るのに1週間かかっていたモデルが半日くらいでできるとか、そういうスピード感ですね。もしかしたらもっと速いかもしれない。コスト的にもまったく文句ないですし、便利に使わせてもらってます。
長谷川:ところで今回、さくらの高火力コンピューティングのラインアップにTesla V100の32GBモデルを追加しました。同時に、これまでの16GBモデルは価格を改定し、初期費用を上げる代わりに月額のランニングコストを引き下げさせていただきました。
中村:それは来年の契約で安くなるってことですか? めっちゃうれしいです(笑)。
長谷川:価格改定の理由なんですが、ディープラーニング用途のお客様は現在、研究規模をどんどん拡大されているところで、サービスの解約がほとんどないんです。われわれがサービス立ち上げ時に想定していたよりも解約率がずっと低いので、これならばさらに踏み込んで、もっと安く計算リソースをご提供できるだろうと。
Ideinさんのように、真剣にディープラーニングの研究開発に取り組んでいて、大量のリソースを24時間ずっと使いたいというお客様はたくさんいらっしゃいます。そういうお客様に対し、1分単位の従量課金ではなく、24時間ご利用いただけるリソースをいかに安く提供できるかという方向性でさくらは努力しています。
それから新しい32GBモデルですが、特にIdeinさんの場合は精度の高い、大規模な深層学習モデルを作りたいという需要がありますよね。GPUの搭載メモリが増えることで、得られるメリットも大きいんじゃないでしょうか。
中村:おっしゃるとおりですね。現状の16GBでも結構なサイズですが、基本的には大きければ大きいほうがいいですから。バッチサイズを大きくすることができれば、より大きなモデルの学習がはかどります。
それから、現状では「GPUのメモリが足りないから解像度を抑えないといけない」「ニューラルネットワークの規模を抑えないといけない」とか、そういうシーンも結構あるんです。たとえば、解析したい画像の解像度を少し上げるだけで、使用メモリはグンと増えますから。そういう制約が減るのはすごくいいと思います。
――最後に、これからのさくらインターネットに期待することがあれば教えてください。
中村:非常に快適に使わせていただいてますし、満足もしているので、あとはどんどん安くなればいいかな、と(笑)。それから……たとえば今回のTesla V100 32GBモデルも、たぶん世界に先駆けてのサービスじゃないですか?
長谷川:そうですね、クラウド事業者で32GBモデルをサービス提供している会社は、まだ見かけないです。
中村:われわれとしてはそういう部分、つまり「さくらさんとお付き合いしていれば最新のものがすぐに使える」という部分に期待してます。こちらは最新のものを使いたいのに、事業者側の都合で待たされるというのはよくある話なので。
長谷川:そこはわれわれも頑張りたいところです。さくらは連結でも600名くらいの小さな会社ですので、お客様から「こういうものが欲しい、使いたい」とご相談いただければ、カスタマイズモデルのようなものもご提供できる。海外のクラウド事業者のほうが体力があるのは事実ですが、われわれは所帯が小さいメリットを生かして、お客様に寄り添うようにしてサービスを提供していきたい。特に大規模なディープラーニングなどに取り組まれているお客様にとっては、そこが活用しやすい部分だと思います。
江草:そうしたちょっと特殊なものも、パブリックサービスの利便性で使っていただける。これからもそういう柔軟さを目指したいですね。
※掲載の記事内容・情報は執筆時点のものです。


